Words Matter: A Comprehensive Guide to LLM Evaluation Techniques
A crisp and clear guide on selecting the LLM evaluation techniques with examples.

Evaluating the performance of Large Language Models (LLMs) is a critical task in the field of artificial intelligence. As these models are increasingly deployed across various applications — from chatbots to content generation — understanding how to measure their effectiveness is essential. This blog post will explore the key evaluation metrics, when to use them, and provide visual aids to enhance comprehension.
Why Evaluate LLMs?
The evaluation of LLMs is vital for several reasons:
- Performance Monitoring: Ensures that models function as intended and meet user expectations.
- Model Comparison: Helps researchers and developers compare different models to select the best one for specific tasks.
- Continuous Improvement: Identifies areas for improvement, guiding further development and fine-tuning of models.
Key Metrics for LLM Evaluation
1. Perplexity
Definition: Perplexity measures how well a language model predicts a sample of text. It quantifies the uncertainty of the model when predicting the next word in a sequence. Formula:

where N is the number of words, and P(xi) is the probability assigned to the i-th word.
When to Use: Perplexity is useful for assessing general language proficiency but does not provide insights into text quality or coherence.
Example: A model with a perplexity score of 30 indicates moderate predictive power; lower scores (e.g., 10) suggest better performance.

2. BLEU Score
Definition: BLEU (Bilingual Evaluation Understudy) measures the similarity between generated text and reference translations, primarily used in machine translation.
Range: Scores range from 0 to 1, with higher scores indicating better performance.
When to Use: BLEU is particularly useful for tasks involving translation or paraphrasing where fidelity to a reference output is crucial.
Example: If an LLM translates a sentence from English to French, a high BLEU score would indicate that its translation closely matches human-generated translations.
3. ROUGE Score
Definition: ROUGE (Recall-Oriented Understudy for Gisting Evaluation) evaluates summarization by comparing n-grams between generated summaries and reference summaries.
When to Use: ROUGE is best suited for summarization tasks where capturing key information from a larger text is essential.
Example: An LLM summarizing an article would be assessed on how many important phrases it retains compared to a human-generated summary.
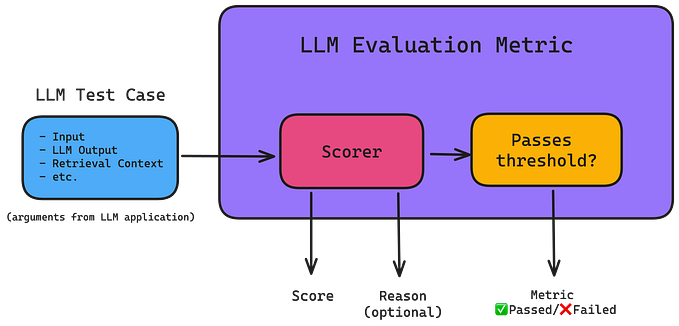
4. Human Evaluation
Definition: Human evaluation involves subjective assessments by human judges who rate the quality of generated responses based on criteria such as relevance, fluency, and coherence.
When to Use: This method is invaluable when evaluating nuanced outputs that automated metrics may not capture effectively.
Example: A panel might evaluate chatbot responses for customer service interactions, assessing how well they address user queries and maintain a conversational tone.
Benchmarking Frameworks
Standardized benchmarks are essential for evaluating LLMs across various tasks:
- GLUE (General Language Understanding Evaluation): Tests language understanding through multiple tasks like sentiment analysis and question answering.
- SuperGLUE: An advanced version of GLUE that includes more complex tasks designed to challenge current models.
- MATH Benchmark: Focuses on evaluating mathematical reasoning capabilities through high-school-level competition problems.
Advanced Evaluation Techniques
- G-Eval Framework
- This framework leverages LLMs themselves to evaluate outputs by generating evaluation steps based on criteria like coherence before scoring them.
2. BERTScore
- Utilizes contextual embeddings from models like BERT to assess semantic similarity between generated texts and reference texts, making it ideal for nuanced evaluations.
3. Task-Specific Metrics
- Metrics tailored for specific applications can provide deeper insights into performance beyond standard metrics. For example, if your application involves summarizing news articles, you might create custom metrics that assess content retention and accuracy against original texts.
Best Practices for Effective Evaluation
To ensure effective evaluation of LLMs, consider these best practices:
- Curate Benchmark Tasks: Design tasks that cover a spectrum from simple to complex.
- Prepare Diverse Datasets: Use representative datasets that have been carefully curated.
- Implement Fine-Tuning: Fine-tune models using prepared datasets.
- Run Continuous Evaluations: Regularly check model performance.
- Benchmark Against Industry Standards: Compare your model’s performance against established benchmarks.
Conclusion
Evaluating Large Language Models involves a combination of quantitative metrics like perplexity, BLEU, and ROUGE scores alongside qualitative assessments through human evaluation. By utilizing standardized benchmarks and advanced frameworks, researchers can gain comprehensive insights into model performance across diverse tasks. As LLMs continue to evolve, ongoing development of new metrics will be essential for accurately measuring their capabilities in real-world applications.
By implementing these strategies and metrics, organizations can ensure that their AI systems reflect their values and serve user needs efficiently.
If you like the article and would like to support me make sure to:
- 👏 Clap for the story (50 claps) and follow me 👉
- 📰 View more content on my medium profile
- 🔔 Follow Me: LinkedIn | Medium | GitHub | Twitter